
G. Dictionary
key → value pairs. Keys are unique identifiers of elements. Values can be of different data type.value based its on key.{key1:value1, key2:value2}dictionary[key]
# Suppose we have three participants in our class: peter (id=1001), yuner (id=1002), benjamin (id=1003).
# Try generating a dictionary of participants' ids and their names.
student_dic={1001:"peter",1002:'yuner',1003:'benjamin'}
student_dic[1001]
# We can expand the dictionary to have more values about students, such as gender and age
student_dic={1001:["peter","M",23],1002:['yuner','F',32],1003:['benjamin','M',24]}
student_dic
We can use method .keys() to access all keys and .values() to access all values.
# Try .keys() and .values() methods.
# How many items are there in student_dic?
Exercise
Create two dictionaries of the top 5 movies on IMDB (https://www.imdb.com/chart/top/).
1.First dictionary: Use ranking as the key. Include movie name, rating and release year as the values.
2.Second dictionary: Use movie name as the key. Include ranking, rating, and release year as the values.
To add new items, you can simply use the following syntax, much similar to variable assignment:
dictionary[key] = value
#add one more movie to the dictionary
H. DataFrame
pandas module, which is equivalent to table in common sense.pd.DataFrame(data=...[,index=...,columns=...]). Arguments in square bracket are optional.pd.read_csv(file path [, indexcol=..., header=...]).dataframe.loc[index]dataframe.iloc[index]dataframe[column_name]dataframe[[column1, column2 ...]]! pip3 install pandas
import pandas as pd
#We have two ways to create a DataFrame, i.e. progressive way and import way.
#1.1: Progressive way BY ROW
a=pd.DataFrame([[1001,'petter','M','HKU'],[1002,'yuner','F','HKBU'],[1003,'benjamin','M','CityU']])
a
#change headers
a.columns=['id','name','gender','affiliation']
a
a.index=['a','b','c']
a
a.columns
#1.2: Progressive way BY COLUMN
a=pd.DataFrame()
a['id']=[1001,1002,1003]
a['name']=['petter','yuner','benjamin']
a['gender']=['M','F','M']
a['affiliation']=['HK','HKBU','CityU']
#check out the index for each row
a.index
a
#assign a column to be index column
a=a.set_index('id')
a
#Retrieve values by index
a.loc[1001]
#Slice dataframe by index
a.loc[1001:1003]
#Retrieve values by relative location
a.iloc[0]
#Slice dataframe by relative location
a.iloc[:3]
#Access a single column/series
a['name']
#Access two columns/series
a[['name','gender']]
#Value comparison
a['gender']=='M'
#filter dataframe based on value comparison results
a[a['gender']=='M']
Download the data here: https://juniorworld.github.io/python-workshop/doc/COMM_journals.csv
#2: Easy way
#format: pd.read_csv(file path [, header=..., index_col=...])
b=pd.read_csv('COMM_journals.csv',header=0,index_col=0)
b
b=pd.read_csv('https://juniorworld.github.io/python-workshop/doc/COMM_journals.csv',header=0,index_col=0)
b
b.head()
b.tail()
Differences in Format/Synatx:
#check the dimensions of the dataframe with .shape attribute
b.shape
#min, max, mode, median, sum, var, std of Journal Impact Factor
We can use methods:
Dataframe.sort_values(column_name[, ascending=True]) to sort dataframe by a columnSeries.value_counts([normalize=False])Dataframe.pivot_table(index=column1, [column=column2,] values=column3, aggfunc=function_name) to generate aggregate cross-tabulation about the dataframeb.sort_values('Journal Impact Factor')
b.sort_values('Journal Impact Factor',ascending=False)
#save Dataframe to a csv file
b.to_csv("output_data.csv")
Download the stackoverflow developer survey data here: https://juniorworld.github.io/python-workshop/doc/stack-overflow-developer-survey-2022-first1000.csv
#read survey data into dataframe c
c = pd.read_csv("https://juniorworld.github.io/python-workshop/doc/stack-overflow-developer-survey-2022-first1000.csv")
c.head()
c.columns
c.shape
#break down dataframe by Gender, EdLevel, and Age
#.value_counts() & .value_counts(normalize=True)
A. File I/O:
open(path[,mode='r']) function..readlines() method will extract all content in the file as a list of strings. One paragraph, one string..write(string) method write the given content to the file, from the beginning of file if mode 'w' is used or from the bottom of file if mode 'a' is used..close() method\n.strip()/ to denote directory# Create a new file named "text.txt" in the current folder
#add three new lines, separated by line break mark \n
#close it
# Create a child folder test
# Create another file named "text2.txt" in the child folder
# Create a file named "text3.txt" in the parent folder
# grandparent folder?
#Open text.txt file
#read the existing lines
#print out the first line
#calculate the length (number of characters, including spaces) of first sentence
B. If/Else Statement
if logical_condition1 :... (else: ...)if a==1: print('yes') #Block A else: print('no') #Block B``` >
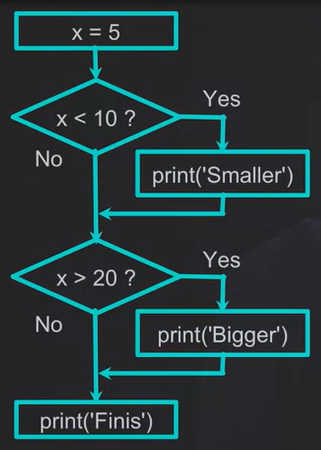
#Use If/Elif/Else statement to realize this decision tree
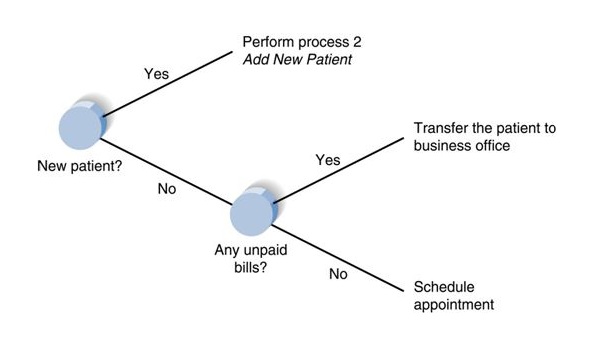
#Demonstration
#Use If/Elif/Else statement to allocate a patient with records as below:
a={'new patient':False,'unpaid bill':False}
